2026
GOFA: Gradient-Oriented Backdoor Attack in Vertical Federated Learning
Ye CHENG, Adachi Naotoshi
International Conference on Electrial Computer and Energy Technologies 2026 ICECET2026
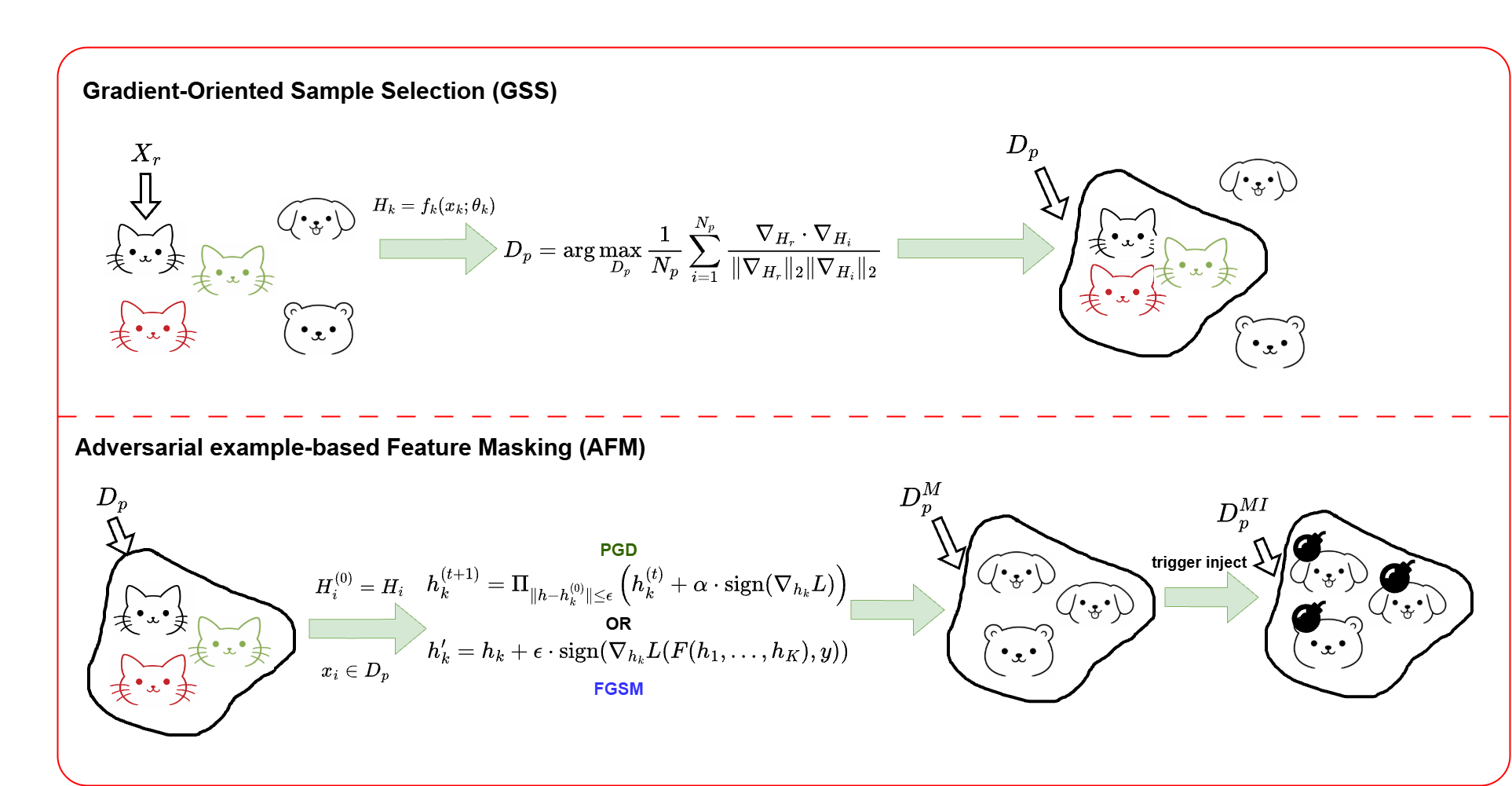
Vertical federated learning (VFL) enables multiple organizations with disjoint feature spaces and overlapping sample identities to collaboratively train machine learning models without sharing raw local data. Despite this privacy-preserving paradigm, VFL remains vulnerable to backdoor attacks. In particular, a malicious passive party can inject carefully crafted triggers into local inputs or intermediate embeddings, causing targeted mispredictions during inference. Existing VFL backdoor attacks (e.g., BadVFL) typically assume that the malicious client has additional knowledge of task labels, which conflicts with the core privacy assumptions of VFL. In this paper, we propose GOFA, a gradient-oriented backdoor attack for VFL. GOFA leverages server-provided gradient feedback to construct a poisoned dataset and applies adversarial-example techniques (e.g., FGSM) to mask original features and strengthen trigger learning. Experiments on CIFAR-10 and UCI-HAR demonstrate the effectiveness of our method across multiple settings.
GOFA: Gradient-Oriented Backdoor Attack in Vertical Federated Learning
Ye CHENG, Adachi Naotoshi
International Conference on Electrial Computer and Energy Technologies 2026 ICECET2026
Vertical federated learning (VFL) enables multiple organizations with disjoint feature spaces and overlapping sample identities to collaboratively train machine learning models without sharing raw local data. Despite this privacy-preserving paradigm, VFL remains vulnerable to backdoor attacks. In particular, a malicious passive party can inject carefully crafted triggers into local inputs or intermediate embeddings, causing targeted mispredictions during inference. Existing VFL backdoor attacks (e.g., BadVFL) typically assume that the malicious client has additional knowledge of task labels, which conflicts with the core privacy assumptions of VFL. In this paper, we propose GOFA, a gradient-oriented backdoor attack for VFL. GOFA leverages server-provided gradient feedback to construct a poisoned dataset and applies adversarial-example techniques (e.g., FGSM) to mask original features and strengthen trigger learning. Experiments on CIFAR-10 and UCI-HAR demonstrate the effectiveness of our method across multiple settings.